语音伪造及检测技术研究综述
1 引言
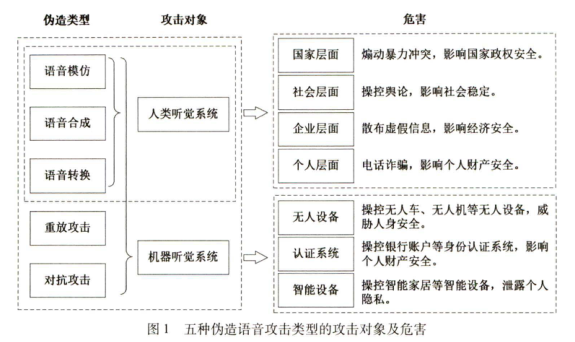
- 语音伪造技术的恶意攻击对象分为人类听觉系统(Human Audio System,HAS)和机器听觉系统两大类
- 针对说话人验证系统(Automatic Speaker Verification,ASV)的恶意攻击,将非法获取目标用户的访问权限
2 语音伪造技术
- 语音伪造的目的是生成目标说话人的声音,以欺骗人类听觉系统(HAS)或自动说话人验证系统(ASV)
- 目前的语音伪造技术主要包括:
- 语音模仿(Impersonation):通过人类模拟产生目标说话人风格的语音,属于非自动化的语音伪造手段
- 语音合成(Text to Speech,TTS):根据给定的语言内容合成目标说话人风格的语音,实现文本到声音的映射
- 语音转换(Voice Conversion,VC):将源说话人的语音转换为目标说话人风格的语音,实现声音到声音的映射
- 重放攻击(Replay Attack,RA):对目标说话人的语音通过设备录制后进行编辑和回放以产生高度逼真的目标说话人语音(常用于攻击ASV系统)
- 对抗攻击(Adversarial Attack):通过对抗样本技术,在语音信号上添加微量扰动实现对ASV系统的攻击
2.1 语音合成
典型的语音合成系统如图2所示
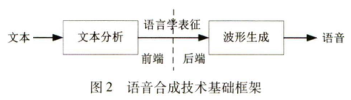
包括:
- 前端文本分析:将输入文本通过规范化、分词、词性标注等步骤生成对应的音素序列、时长预测等信息
- 后端语音波形生成:根据文本分析生成的语言规范合成目标说话人的语音波形
传统语音合成主要包括波形拼接法和参数生成法
- 波形拼接法
- 将自然语音数据中的语音单元按照一定的规则拼接,合成与目标说话人高度相似且自然的语音,包括语料库收集、声学单元选取、拼接伪造等步骤
- 代表性工作:基音同步叠加的PSOLA技术、利用隐马尔可夫模型(Hidden Markov Model,HMM)限制目标单元韵律参数的单元选择系统
- 适用于某些特定领域(天气预报、报时等)
- 使用真实语音片段,最大限度保留语音音质,但是需要大量目标说话人语料,对于不同领域的文本合成稳定性不强,容易被人或机器识别
- 参数生成法
- 通过声学模型预测声学参数,将声学参数通过声码器合成目标说话人语音
- 代表性工作:基于HMM的统计参数合成方法、基于DNN的参数合成方法
- 输出语音稳定流畅,但受限于参数合成器的缺陷以及统计建模的损失
- 波形拼接法
采用深度学习方法的技术主要包括管道式(Pipeline)语音合成和端到端式语音合成两类
- 管道式语音合成
- 三个模块
- 文本分析:根据输入文本进行韵律预测和每个音素的时长预测
- 声学模型:建立文本特征和声学特征之间的联系,根据文本分析的输出经由DNN映射到声学特征
- 声码器:实现声学参数到语音波形的转换
- 限制:多个模块之间会产生误差积累,需要高昂成本的文本标注以及文本特征和声学特征的强制对齐
- 三个模块
- 端到端式语音合成
- 实现了直接输入文本或注音字符,输出音频波形
- 自回归语音合成
- 基于序列到序列的生成模型,语音合成效果优,但速度较慢
- 2016Google提出的WaveNet语音合成算法
- 通过扩张因果卷积网络根据当前时刻采样点生成下一采样点
- 直接对原始语音数据进行建模,避免了声码器对语音进行参数化时导致的音质损失
- 无法实现输入文本或标注音符到输出语音的直接转换
- 2017年第一个端到端语音合成系统Tacotron
- 引入了注意力机制,输入文本或注音字符,输出线性语谱图,再通过Griffin-Lim算法生成语音波形
- 所有特征模型可学习调优,便于添加语种、音色、情感等限制条件
- 但模型复杂,纠错能力和人为干预能力差,音质不如WaveNet
- 2018年Tacotron2简化了前端模型结构
- 基于文本输入生成梅尔语谱图
- 通过改进的WaveNet声码器合成语音波形
- 2021年提出Wave-Tacotron端到端语音合成系统
- 通过在自回归解码器中添加规范化流来扩展Tacotron系统
- 不生成中间特征,无需声码器实现文本到波形的端到端语音合成
- 非自回归语音合成
- 基于全并行网络结构,通过一次前馈计算生成整句语音,极大提升速度,可控性强且语音合成质量接近自回归模型效果
- 2019年——基于源滤波的实时参数语音合成模型
- 基于频谱距离和相位距离的训练准则
- 对给定的输入声学特征,通过源模块、基音F0和谐波加噪模型生成正弦激励信号
- 然后通过级联扩张卷积和长短期记忆网络(LSTM)将激励信号和频谱特征转换成语音波形
- 2019年——基于Transformer的语音合成系统FastSpeech
- 从基于编码器-解码器的教室模型中提取注意力对齐来预测音素持续时间
- 通过长度调节扩展源音素序列以匹配目标音素序列的长度,并生成梅尔谱图
- 语音质量与自回归模型相当,极大提升了语音生成速度
- 2020年——FastSpeech2
- 解决了FastSpeech中师生蒸馏复杂且耗时的问题
- 引入更多语音变化信息,进一步提升语音音质和生成速度
- 2021年——Parallel Tacotron
- 基于变分自编码器(VAE)的残差编码器扩展了Tacotron系统
- 2021年——基于FastSpeech的全并行语音合成系统FastPitch
- 在语音生成过程中改变基音轮廓预测以匹配话语语义
- 2021年——可快速生成高质量语音的多频带MelGAN模型
- 将频谱图作为生成器的输入,输出子带表示,将其合并成全波段信号表示后输入鉴别器
- 同时使用多分辨率STFT损失替换原始的特征匹配损失
- 管道式语音合成
3 伪造语音检测技术
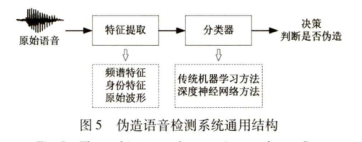
3.1 伪造语音检测系统通用结构
- 典型的伪造语音检测系统一般由前后端两部分组成
- 前端:分析语音信号提取具有区分性的特征
- 后端:分类判断语音是真实语音还是伪造语音
- 基于深度学习的系统前端提取输入神经网络的语音特征,后端通过神经网络学习特征的高级表示,进行分类判决
3.2 攻击场景和评价指标
3.2.1 攻击场景
身份认证应用中常用的ASV系统结构及其主要可能存在的攻击节点:
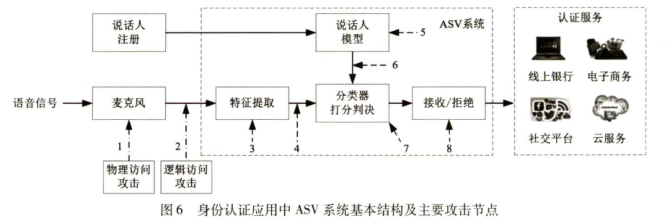
- 节点1和2为直接攻击节点,发生在语音声纹特征提取之前
- 节点3-8为间接攻击节点,攻击者可以介入ASV内部处理流程中的各个操作环节
根据伪造语音输入目标ASV系统的途径,可将伪造语音攻击分为物理访问(Physical Access,PA)攻击和逻辑访问(Logical Access,LA)攻击
- PA中语音样本以空气传播的方式通过麦克风捕获后输入目标ASV系统
- LA中语音样本直接输入目标ASV系统
- 伪造语音检测常用数据集可分为LA和PA两类
- LA场景的伪造语音类型包括转换语音、合成语音等
- PA场景的伪造语音包括重放语音
3.2.2 评价指标
伪造语音检测算法的常用性能指标包括等错误率(Equal Error Rate,EER)和串联检测代价函数(tandem Detection Cost Function,t-DCF)
等错误率(EER)
等错误率(EER)是错误接受率(False Accept Rate,FAR)和错误拒绝率(Fasle Rejection Rate,FRR)相等时的错误率
- 错误接受:将伪造语音错误分类成真实语音
- 错误拒绝:将真实语音错误分类为伪造语音
给定检测系统的检测分数和阈值θ,错误接受率和错误拒绝率可分别按式(1)和式(2)计算:
式(1)和式(2)分别是θ的单调递减函数和单调递增函数
阈值为θ时的等错误率EER对应于式(1)和式(2)相等时的值,即
等错误率越小代表伪造语音检测系统的效果越好,但该指标未考虑伪造语音检测系统对ASV系统可靠性的影响
串联检测代价函数(t-DCF)
并非独立评估,而是反映了实际情况下伪造语音和伪造语音检测系统对ASV系统性能共同产生的影响
实际中ASV系统可能遇到合法用户、临时冒充的非法用户以及试图恶意操作ASV决策的攻击者,该指标综合考虑了不同情况下的误判代价
简要计算过程如下
- 系数β取决于实际中的伪造攻击优先级、误判成本以及ASV系统的检测性能(FA和FR等)
t-DCF越小说明检测系统的泛化性能越好
3.3 针对语音合成/转换的伪造语音检测技术
- 早期语音合成检测方案主要考虑语音信号、声纹特征和频谱分布等生物信息的差异特征
- 部分研究集中于声码器和自然语音之间的声学差异
- 传统语音合成方法难以建立可靠的韵律模型,部分工作使用基频信息进行检测:
- 统计参数合成方法生成语音的基频F0通常过度平滑
- 波形拼接方法生成语音的单元连接点处F0跳跃
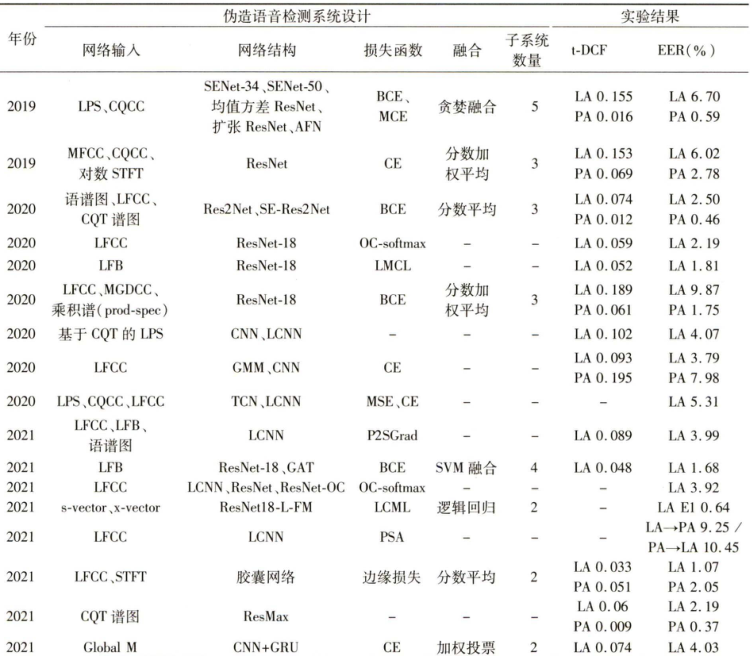
- 基于DNN的合成语音检测系统的研究主要集中在特征提取方法,特征表示学习网络结构设计和损失函数设计三个方面。
3.3.1 前端特征提取
- 前端工作主要研究如何提取伪造语音中可区分于真实语音的特征以输入后端进行判决(如伪造语音通常缺少频谱和时间细节信息)
- 目前伪造语音检测的常用特征主要分为三大类:
- 频谱特征(最广泛)
- 身份特征
- 原始波形
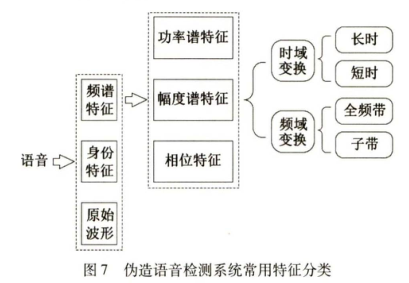
- 短时功率谱特征
- 描述了信号功率随频率的变化情况
- 常用的短时功率谱特征
- 对数功率谱
- 基于滤波器的倒谱系数(Filter-Based Cepstral Coefficient,FBCC):梅尔频率倒谱系数(MFCC)、矩形滤波倒谱系数(LFCC)
- 基于全极点语音建模参数的倒谱系数:线性预测倒谱系数(LPCC)
- 由于伪造语音无法很好地模拟语音的时间特征,因此倒谱的高阶系数和一阶、二阶动态差分系数都有利于进行伪造语音检测

- 短时幅度谱特征
- 对数幅度谱(Log Magnitude Spectrum,LMS):包含语音信号的细节信息,如共振峰、基音和元音的谐波结。
- 残差对数幅度谱(Residual Log Magnitude Spectrum,RLMS):从线性预测编码(LPC)残差波形中提取,包含谐波等频谱细节信息
- 与LMS相比,RLMS消除了共振峰影响。
- 短时相位特征
- 声码器重建波形时会忽略相位信息,因此短时相位特征是检测伪造语音的有效特征之一
- 由傅里叶变换得到的相位谱存在相位扭曲,需对其进行处理以得到稳定有效的相位特征
- 常用的相位特征:
- 群延迟(Group Delay,GD)
- 改进的群延迟(Modified Group Delay,MGD)
- 基带相位差(Baseband Phase Difference,BPD)
- 瞬时频率导数(Instantaneous Frequency Derivative,IF)
- 相对相位偏移(Relative Phase Shift,RPS)

- 基于长时变换的特征
- 耳蜗滤波器瞬时频率倒谱系数(CFCCIF)
- 基于长时常数Q变换的倒谱系数(CQCC)
- 专门为伪造语音检测工作设计的特征,基于长时窗口恒定Q变换(CQT),对LA和PA场景下不同类别的攻击均有效

- 基于子带变换的特征
- 伪造语音的干扰存在于语音的子带级别,只有在同频带中提取高分辨率特征才能可靠地提取这些干扰信息
- 子带变换相比于全频带变换更可靠地捕捉伪造语音中特定频段内的精细特征
- 三种基于子带变换的特征:
- 恒Q等子带变换(CQ-EST)
- 恒Q倍频程子带变换(CQ-OST)
- 离散傅里叶梅尔子带变换(DF-MST)
- 通过静态系数、动态差分系数和加速度系数的特征组合可达到远超CQCC、MFCC特征的效果

- 目前工作基本采用融合多个不同前端的子系统的方法,综合不同特征的优势以达到更好检测效果
3.3.2 后端分类模型
- 借助神经网络的特征学习能力,最新的检测系统后端对前端输入特征学习其高级特征表示后再进行分类
- 目前大多数工作针对特定攻击或基于固定数据集,单个系统无法高效地检测多种不同的伪造攻击(TTS、VC和TTS-VC混合等)和训练集中不存在的未知攻击
- 实际中难以提前获知攻击类型,因此最新的研究重点普遍集中于提高检测的泛化性——能跨越不同伪造攻击类型并可抵抗不同通道环境噪声干扰的通用检测系统
- 目前,基于DNN的研究工作主要包括深度神经网络结构、损失函数和深度网络训练方法
- 深度神经网络结构
- 后端网络一般采用基于卷积神经网络(CNN)的架构,如轻量卷积神经网络(LCNN)、残差网络(ResNet)、挤压-激励网络(SENet)等
- ResNet
- 为解决深层网络的退化和梯度消失问题(较低层难以在训练中接受有用的更新信息)提出
- 核心思想:使用跳过连接作为捷径,减少深层网络的训练参数,允许训练过程中参数更新更快地向较低层传播
- LCNN
- 可在减少计算成本和存储空间的情况下处理带有大量噪声标签的大规模数据
- 核心:每个卷积层后引入了最大特征图(Max Feature Map,MFM)激活函数
- 相比ReLU,MFM激活后得到的特征图更紧密,同时可实现特征选择和特征降维
- SENet
- 核心:通过挤压-激励操作显示建模通道之间的相互依赖性
- 先对特征图进行挤压操作得到通道级全局特征,再对全局特征做激励以学习各通道间关系
- 为不同通道分配不同影响权重,从而提高了模型专注于伪造检测最相关的通道信息能力
- 损失函数
- 常用交叉熵损失(softmax损失)或AM-softmax损失
- 主要针对现有检测系统对未知数据泛化能力不佳的问题进行损失设计
- 增强边缘余弦损失函数(LMCL)
- 将softmax损失重整为余弦损失,迫使DNN学习可最大化类间方差并最小化类内方差的特征表示
- OC-softmax
- 通过压缩真实语音的表示来区分真实与伪造语音
- 基于核密度估计(KDE)的损失函数
- 通过估计每个小批次内数据类的概率密度函数,计算每个小批次内所有训练类的KDE损失
- 使用概率-相似度梯度(P2SGrad)的无超参数的均方误差损失函数
- 通过总结比较常用的不同损失函数的性能,基于边缘的softmax对超参数设置敏感的问题提出
- 深度网络训练方法
- 从此角度研究如何提高检测系统的泛化能力,如采用自监督学习、域自适应学习、对抗训练等
- 基于多任务自监督学习的伪造语音检测方案SSAD
- 使用基于时域卷积网络(TCN)的SSAD编码器提取原始音频的深层表示,同时通过最小化回归任务和二分类任务的损失帮助编码器获取更好的高级表示
- SSAD提取高维特征后输入LCNN-big网络进行判别
- 为解决数据集中信道不匹配的问题,提出了多任务学习和对抗训练两种网络
- 多任务学习网络中增加了信道分类器
- 对抗训练网络在前者基础上在信道分类器前添加梯度反转层,形成最大最小化的对抗训练,当训练稳定时,网络可学习到无关于信道影响的深度特征表示
- 使用连续学习方法训练伪造语音检测系统DFWF
- 可帮助减少对过去知识的遗忘
- 同时通过在真实语音中增加额外的正样本对齐(PSA)约束,保持真实语音特征表示分布的一致性
4 伪造语音检测竞赛
- 伪造语音检测领域内规模最大、最全面的挑战赛,是由英国爱丁堡大学、法国EURECOM、日本NEC、东芬兰大学等多个研究机构共同组织发起的两年一度的ASVspoof 挑战赛(Automatic Speaker VerificationSpoofing And Countermeasures Challenge)
- 该赛事旨在通过发布公开数据集并组织竞争性评估来促进ASV伪造语音检测技术的发展
5 相关数据集

5.1 ASVspoof挑战赛数据集
- ASVspoof2015数据集是第一个用于伪造和检测研究的主要数据集,仅针对LA场景,由真实语音和合成/转换语音组成
- ASVspoof2019有LA和PA两个子集,LA子集包含真实和合成/转换语音,PA子集包含真实和重放语音,在一个模拟且可控的声学环境中创建,以控制重放语音中的非受控音素
5.2 AVspoof数据集
- 包含合成、转换、重放三种伪造攻击
- 测试集中引入了未知重放攻击
6 工具资源及相关源代码


7 伪造语音检测未来研究方向
- 高泛化性检测
- 依赖特定数据集或伪造方法的训练数据种类单一且同分布,泛化能力较弱
- 未来应进一步探索有效的多角度深度融合特征以及有效的集成算法
- 少样本检测
- 现有的伪造语音检测大都依赖于大规模、高质量的深度伪造数据集
- 未来应更多地探索基于小样本的自监督学习等技术,保证检测效果的前提下,有效降低模型训练成本
- 鲁棒检测
- 现有的伪造语音检测方法容易在训练集上过拟合,对经过重压缩、加噪等处理后的语音检测鲁棒性较差
- 未来应探索鲁棒的检测算法,如利用对抗样本对检测模型进行对抗训练,或在模型建立的不同阶段,探索不同预处理方法对检测算法鲁棒性的影响
- 活体特征检测
- 现有伪造语音绝大多数没有底噪和背景杂音,但真实语音存在录音底噪、环境噪声、喷麦等
- 未来应将上述活体特征作为辅助信息
- 多模态检测
- 现有的多媒体伪造视频大多通过画面和语音结合以达到更逼真的伪造效果
- 未来应探索伪造数据的多模态检测
- 特定说话人风格检测
- 现有的伪造语音检测方法可以以高自然度模拟目标说话人的音色,但往往忽视了其独特灵活的口语语言特征,如口头禅、赘语、口音、发音习惯等
- 未来应探究特定说话人的语言风格,捕捉能体现说话人个体言语特点的有效特征,以便检测音频真伪
语音伪造及检测技术研究综述
http://example.com/2022/10/19/语音伪造及检测技术研究综述/